2025年天天免费资料,2025 一看就懂的XGBoost原理(转)
网址链接为,https://zhuanlan.zhihu.com/p/83901304。
1. XGBoost简介
XGBoost的全称是eXtreme Gradient Boosting,它是一个经过优化的库,这个库属于分布式梯度提升类型,其目的在于实现高效、灵活以及可移植,XGBoost是用于大规模并行boosting tree的工具,它是当前最快且最好的开源boosting tree工具包,相比常见的工具包速度要快10倍以上。在数据科学领域当中新澳门天天免费谜语解法答案,存在着数量众多的Kaggle选手,他们选用XGBoost这种工具来开展数据挖掘比赛,它还是各大数据科学方面赛事的必杀武器,在工业界大规模类型的数据范畴里,XGBoost的分布式版本具备广泛的可移植特性,它能够支持在Kubernetes、Hadoop、SGE、MPI、Dask等诸多个分布式环境之上运行,这就让它能够很好地去解决工业界大规模数据所产生的问题。本文会针对XGBoost的数学原理展开呈现,还会就其工程实现予以介绍,之后会阐述XGBoost的优点与缺点,并且在最终给出面试期间常常碰到的有关XGBoost的问题。
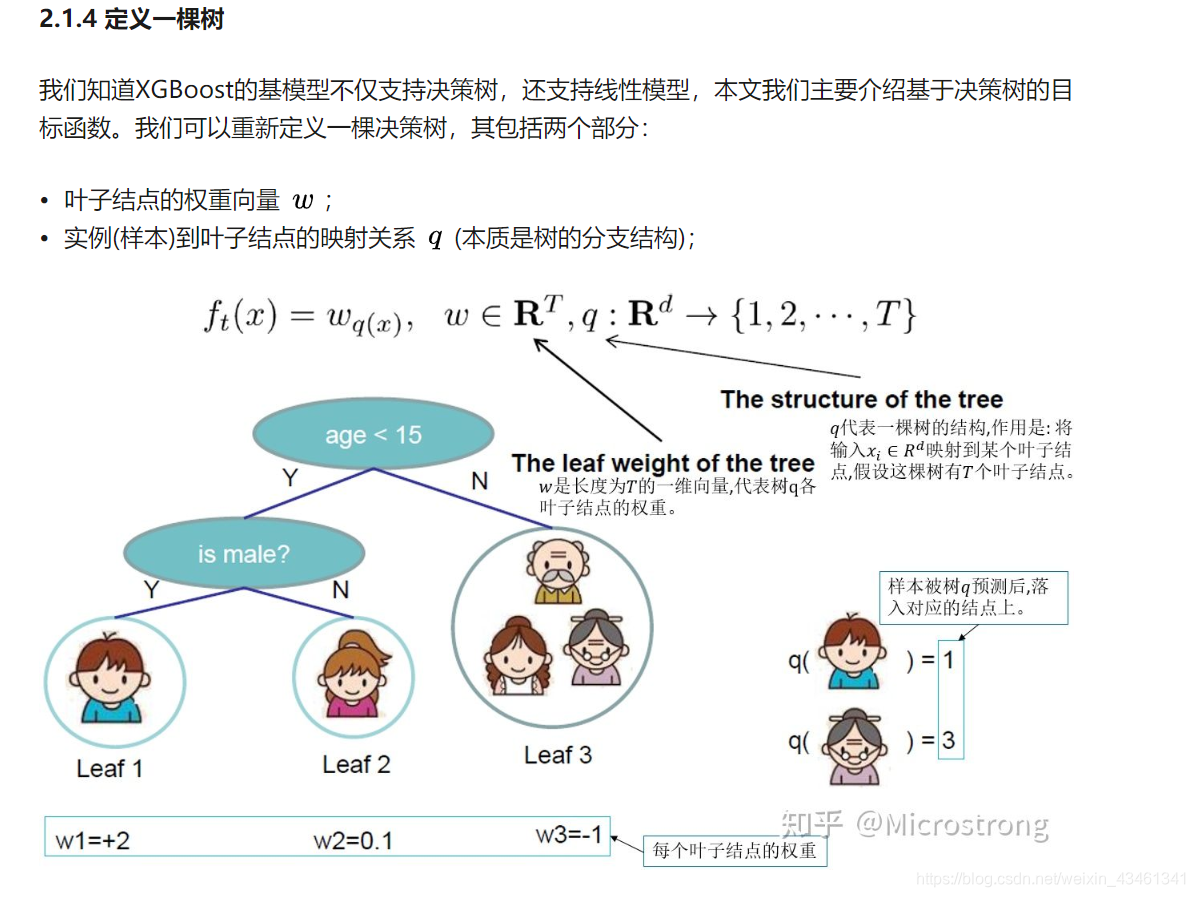
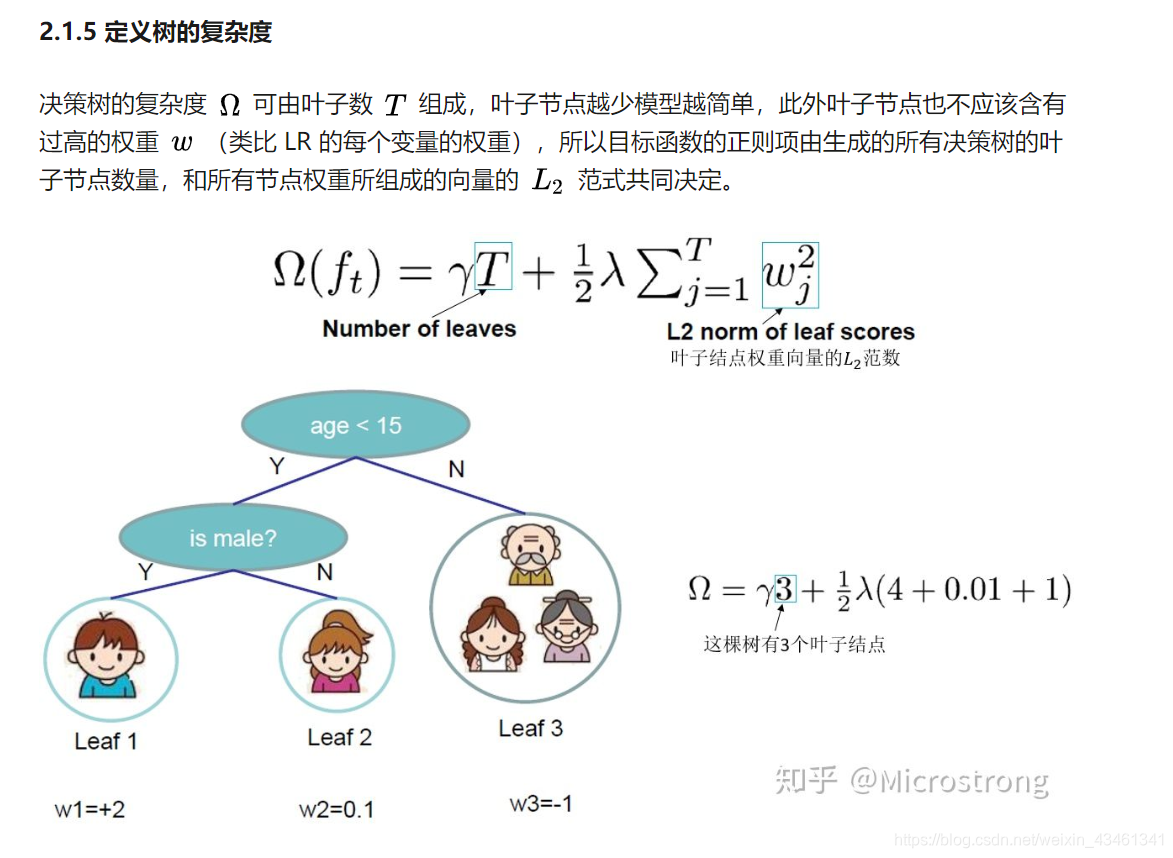
2. 关于XGBoost的原理推导,2.1 起始于目标函数,进而生成一棵树。
XGBoost以及GBDT这两者均为boosting方法,除去在工程实现、对问题进行解决方面存在些许差异之外,最大的不同之处便是目标函数的定义。所以,在本文之中,我们自目标函数着手去探究XGBoost的基本原理。。













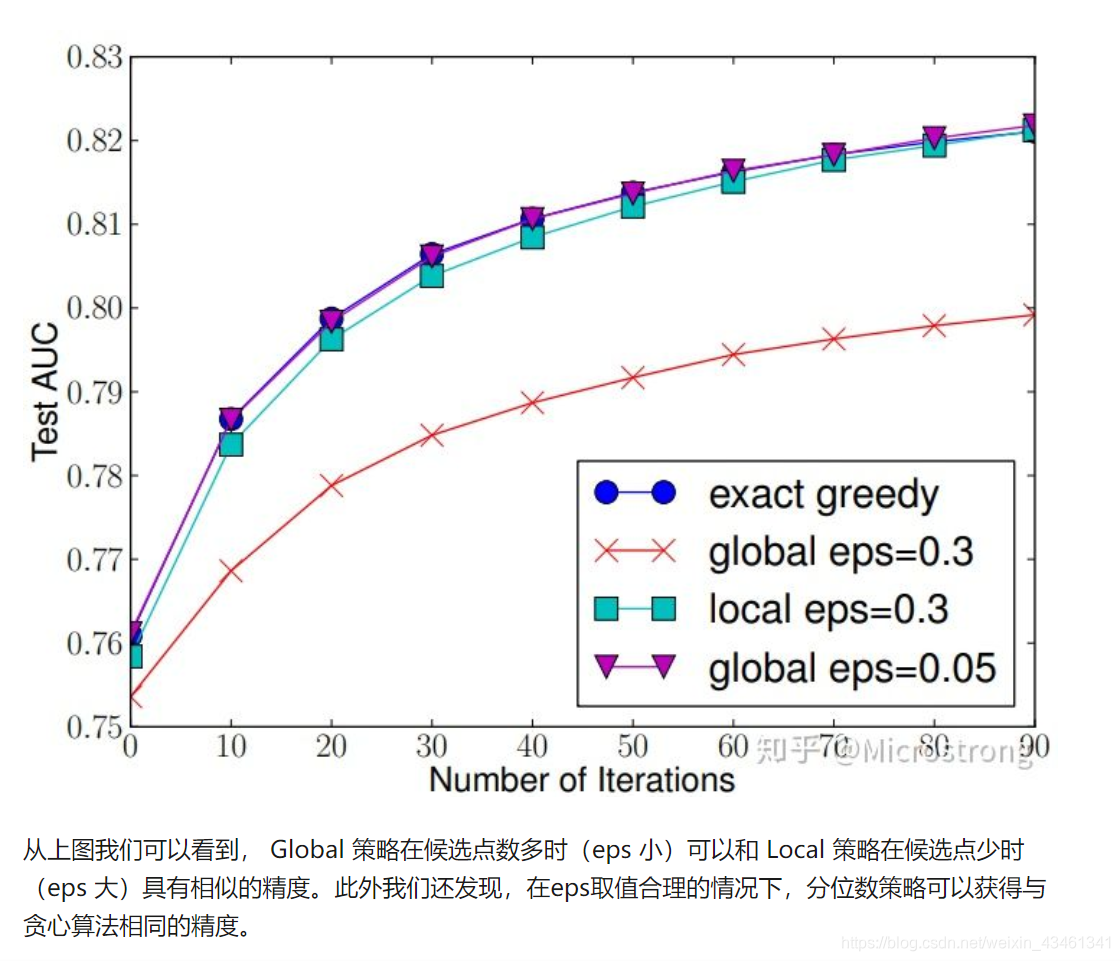
通过观察分裂之后所获得的收益,我们能够发现,节点的划分并不必然会致使结果朝着更好的方向发展。这是由于我们存在着一个针对引入新叶子的惩罚项,也就是说,当引入的分割所带来的增益小于某一个阀值之际,我们是能够将这个分割予以剪掉的。



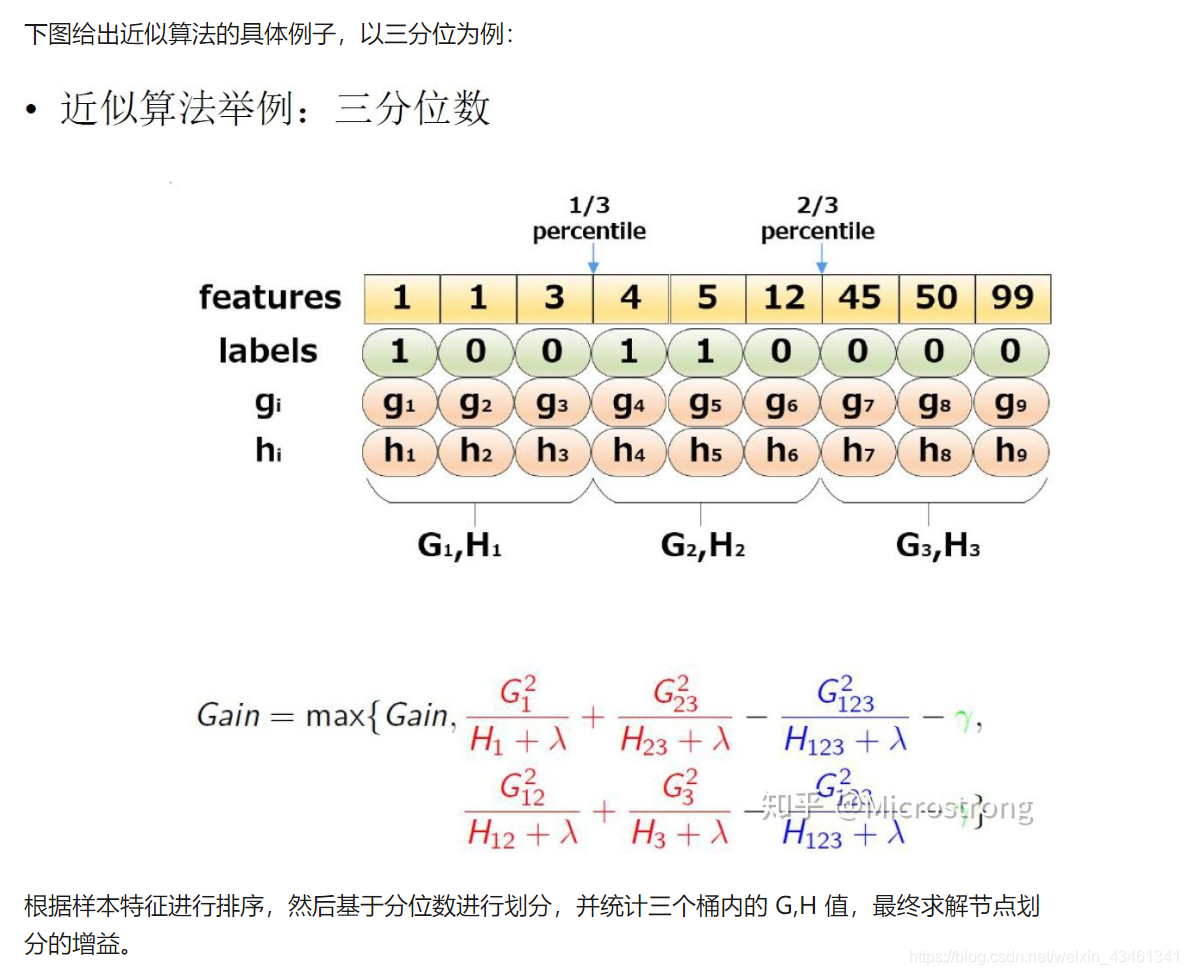


2.2.3 稀疏感知算法
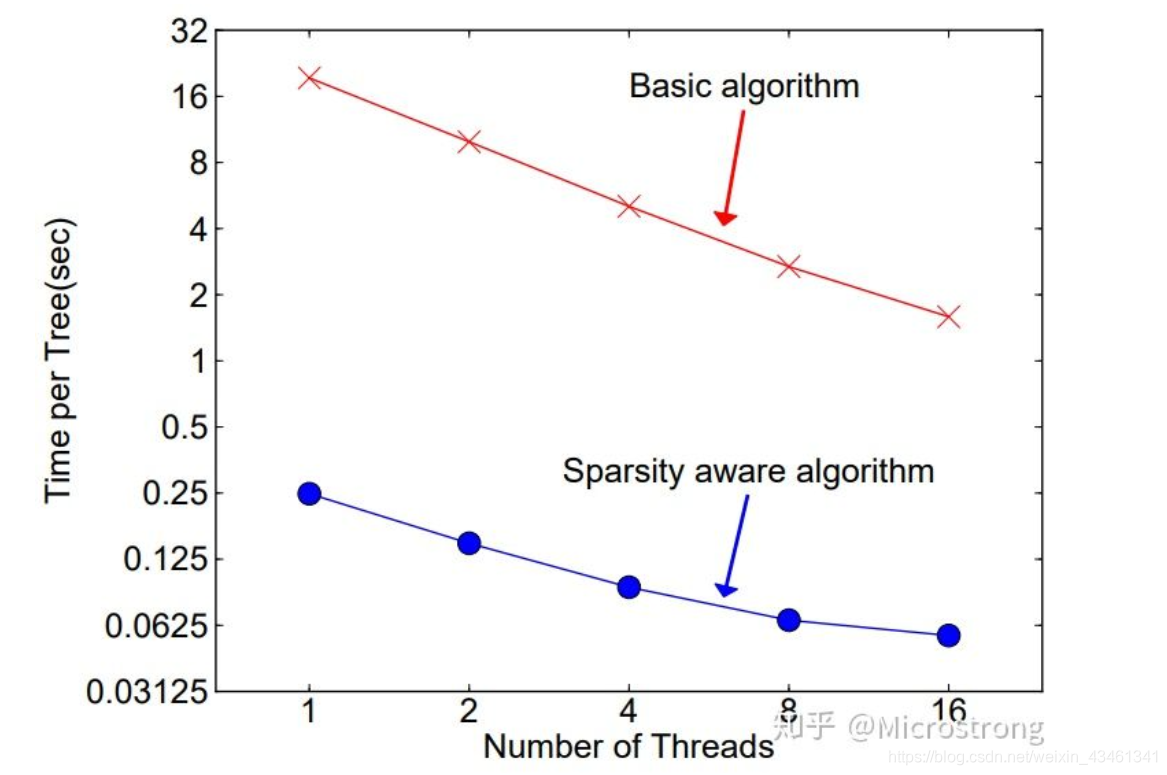
在实际工程里,通常会出现输入值呈现为稀疏状态的情形,举例来说,数据的缺少、one - hot编码这两种状况,均能够致使输入数据变得稀疏,XGBoost在构建树的节点进程中,仅仅会考量非缺失值的数据遍历,并且为每个节点增添了一个缺省方向,当样本对应的特征值出现缺失时,能够被归类至缺省方向上,最优的缺省方向能够从数据当中学习获取,至于怎样学到缺省值的分支,实际上十分简单,就是分别去枚举特征缺省的样本归为左右分支之后所产生的增益,挑选增益最大的枚举项,此枚举项就是最优缺省方向。
构建树时,需枚举特征缺失的样本,乍看算法会多上约一倍计算量,但实则不然,算法迭代中,仅考虑非缺失值数据遍历,缺失值数据直接分到左右节点,需遍历样本量大幅减小,作者于Allstate - 10K数据集做实验,从结果可知稀疏算法处理数据比普通算法快超50倍。


4. XGBoost的优缺点
4.1 优点
4.2 缺点
(1)基于XGBoost原生接口的分类
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
# read in the iris data
iris = load_iris()
X = iris.data
y = iris.target
# split train data and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565)
# set XGBoost's parameters
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 回归任务设置为:'objective': 'reg:gamma',
'num_class': 3, # 回归任务没有这个参数
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
plst = params.items()
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 500
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 计算准确率
cnt1 = 0
cnt2 = 0
for i in range(len(y_test)):
if ans[i] == y_test[i]:
cnt1 += 1
else:
cnt2 += 1
print("Accuracy: %.2f %% " % (100 * cnt1 / (cnt1 + cnt2)))
# 显示重要特征
plot_importance(model)
plt.show()
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
import xgboost as xgb
from sklearn.metrics import mean_absolute_error
# 1.读文件
data = pd.read_csv('./dataset/train.csv')
data.dropna(axis=0, subset=['SalePrice'], inplace=True)
# 2.切分数据输入:特征 输出:预测目标变量
y = data.SalePrice
X = data.drop(['SalePrice'], axis=1).select_dtypes(exclude=['object'])
# 3.切分训练集、测试集,切分比例7.5 : 2.5
train_X, test_X, train_y, test_y = train_test_split(X.values, y.values, test_size=0.25)
# 4.空值处理,默认方法:使用特征列的平均值进行填充
my_imputer = SimpleImputer()
train_X = my_imputer.fit_transform(train_X)
test_X = my_imputer.transform(test_X)
# 5.调用XGBoost模型,使用训练集数据进行训练(拟合)
# Add verbosity=2 to print messages while running boosting
my_model = xgb.XGBRegressor(objective='reg:squarederror', verbosity=2) # xgb.XGBClassifier() XGBoost分类模型
my_model.fit(train_X, train_y, verbose=False)
# 6.使用模型对测试集数据进行预测
predictions = my_model.predict(test_X)
# 7.对模型的预测结果进行评判(平均绝对误差)
print("Mean Absolute Error : " + str(mean_absolute_error(predictions, test_y)))
6. 关于XGBoost若干问题的思考
6.1 XGBoost与GBDT的联系和区别有哪些?
GBDT属于机器学习算法,XGBoost是针对该算法的工程实现。
(2)正则项:于使用CART当作基分类器之际,XGBoost明确地添加了正则项用以把控模型的复杂度,这对预防过拟合有益,进而提升模型的泛化能力。
(3)导数相关情况:GBDT于模型训练之际,仅仅运用了代价函数的一阶导数方面的信息,XGBoost针对代价函数开展二阶泰勒展开,能够一并运用一阶以及二阶导数。
(4)基分类器,传统的GBDT把CART用作基分类器,XGBoost对多种类型的基分类器予以支持,像线性分类器这样的。
(5)子采样,传统的GBDT,在每一轮迭代的时候,那可是使用全部的数据,而XGBoost,却采用了与随机森林类似的策略,它是支持对数据进行采样。
(6)缺失值处理:传统的GBDT未曾做缺失值处理的设计,XGBoost可自动学习得出缺失值的处理策略。
传统GBDT未进行并行化设计,注意并非tree维度的并行,而是特征维度的并行,(7)是并行化。XGBoost预先依特征值对每个特征排好序,存储成块结构2025天天彩资料大全最新版,分裂结点时可采用多线程并行查找每个特征的最佳分割点,极大提高训练速度。
6.2 为什么XGBoost泰勒二阶展开后效果就比较好呢?
从会想到引入泰勒二阶的缘由角度来讲(具备可扩展性),XGBoost官网上表明,目标函数是MSE时,展开呈现一阶项(残差)加上二阶项的样式,然而其他目标函数,像logistic loss的展开样式不存在这般样式。为了拥有同样的样式,故而运用泰勒展开来获取二阶项,如此便能将领MSE推导的那套直接运用到其他自定义损失函数上。简单来讲,就是为了统一损失函数求导的样式以支持自定义损失函数。就关于为何要在形式方面跟MSE达成统一呢?原因在于MSE属于最为普遍并且常用的损失函数,并且它求导最为容易,求导之后的形式也相当简单。故而从理论上来说,只要损失函数形式跟MSE统一了,那么仅仅推导MSE就行了。
(2)针对二阶导数自身具备的性质,也就是基于为何要运用泰勒二阶展开这个角度来讲(精准性方面):二阶信息能够促使梯度收敛得更快且更为准确。此情况在优化算法里的牛顿法当中已得到证实。能够简单地认定一阶导数指引着梯度的方向,二阶导数指引着梯度方向会怎样发生变化。简要来讲,相较于GBDT的一阶泰勒展开,XGBoost采用二阶泰勒展开,能够更为精准地去逼近真实的损失函数。
6.3 XGBoost对缺失值是怎么处理的?
于平常的GBDT策略里,针对缺失值的办法是先手动去对缺失值予以填充,接着当作有值的特征来开展处理,然而如此人工填充不见得精准,并且没什么理论依据。而XGBoost所采取的策略是先不去处理那些值缺失的样本,借助那些有值的样本弄出分裂点,在遍历每个有值特征之际,试着把缺失样本划入左子树以及右子树,挑选让损失最优的值作为分裂点。
6.4 XGBoost为什么可以并行训练?
这里的XGBoost并行,并非是指每棵树能够并行开展训练,XGBoost实际上依旧运用boosting思想,每棵树在训练之前,得等前面的树训练结束之后才可以着手训练。
(2)XGBoost的并行,是指特征维度的并行,在训练以前,每个特征依据特征值对样本开展预排序,且存储成Block结构,在后续查找特征分割点的时候能够重复利用,并且特征已然被存储成一个个block结构,那样在找寻每个特征的最佳分割点时,能够借用多线程对每个block开展并行计算。
7. Reference
鉴于所参考的文献数量颇众,我会就行文每一部分着重参考了哪些文章,予以确切详细的标注。
XGBoost论文解读:
2016年,陈T和格斯特林C出版了《XGBoost:一个可扩展的树提升系统》 ,没错呀,就是这样的。
【2】Tianqi Chen所拥有的XGBoost的Slides2025天天彩资料免费版官网,其地址呈现为:https://homes.cs.washington.edu/~tqchen/data/pdf/BoostedTree.pdf。
关于xgboost的理解,金贵涛所撰写的该篇文章,位于知乎这样一个平台,其链接为https://zhuanlan.zhihu.com/p/75217528。
CTR预估,论文精读其一为XGBoost,其地址是https://blog.csdn.net/Dby_freedom/article/details/84301725。
知乎上一篇由Salon sai所写的关于【5】XGBoost论文阅读及其原理的文章,链接为https://zhuanlan.zhihu.com/p/36794802。
【6】XGBoost论文进行翻译,同时添加个人注释,其地址为:https://blog.csdn.net/qdbszsj/article/details/79615712。
XGBoost算法讲解:
【7】XGBoost有着超级详细的推导过程,终于有其他人将其讲解得清楚明白了。地址为:https://mp.weixin.qq.com/s/wLE9yb7MtE208IVLFlZNkw。
【8】终于,有其他人把XGBoost以及LightGBM讲清晰了,这可是项目里最为主流的集成算法。其地址为:https://mp.weixin.qq.com/s/LoX987dypDg8jbeTJMpEPQ。
有哪些区别,存在于机器学习算法里的GBDT与XGBOOST之间呢,这是weapon的回答,来自知乎这个平台,链接是https://www.zhihu.com/question/41354392/answer/98658997。
,关于【10】GBDT算法定理以及系统设计的简要介绍,wepon,其地址为:http://wepon.me/files/gbdt.pdf。
XGBoost实例:
在【11】中提到的 Kaggle 神器 xgboost,其对应的地址是,https://www.jianshu.com/p/7e0e2d66b3d4。
干货,XGBoost在携程搜索排序里的应用,地址是,https://mp.weixin.qq.com/s/X4K6UFZPxL05v2uolId7Lw。
在知乎上,有一篇由章华燕所写的文章,其标题为【13】史上最详细的XGBoost实战,链接为https://zhuanlan.zhihu.com/p/31182879。
知乎上一篇人工智能学术前沿的文章,是关于【14】XGBoost模型构建流程及模型参数微调(附房价预测代码讲解),链接为https://zhuanlan.zhihu.com/p/61150141。
XGBoost面试题:
收藏版 | 20道关于XGBoost的面试题目,你知晓几个?(上篇),链接地址为:https://mp.weixin.qq.com/s/_QgnYoW827GDgVH9lexkNA ,此乃第【15】条内容。
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论